




Pruebas sobre subregistro delictivo
¿En México se manipula la información oficial sobre incidencia delictiva? ¿Es posible asumir que sucede en todo nuestro país o algunos gobiernos estatales son más propensos que otros a recurrir a esta estrategia?
Jimena David (@jimena_dag), Jonathan Furszyfer (@JonFdr) y Jesús Gallegos / Animal Político
¿Podemos confiar en la información delictiva del fuero común producida por el gobierno? De acuerdo con la Encuesta Nacional de Acceso a la Información Pública y Protección de Datos Personales, 2016[1] (Inegi 2016), cuatro de cada cinco residentes urbanos en México desconfían de la información que publica el gobierno sobre seguridad pública, narcotráfico y delincuencia en su entidad federativa. Adicionalmente, uno de cada dos respondientes considera que esta información ha sido manipulada.
Más allá de la percepción de la opinión pública, se deben realizar análisis estadísticamente robustos[2] que permitan responder la pregunta anterior, para el caso mexicano.
Por otra parte, de ocurrir la manipulación, ¿es posible asumir que sucede en todo nuestro país o algunos gobiernos estatales son más propensos que otros a recurrir a esta estrategia?
Como un esfuerzo para estudiar posibles actos de manipulación de estadísticas delictivas, México Evalúa acaba de publicar un estudio que analiza a las 32 entidades federativas y a cada uno de los gobiernos que las han administrado, desde enero de 1997 hasta agosto de 2016. En particular, nuestra investigación analiza los homicidios dolosos y culposos[3] registrados en la información sobre incidencia delictiva del fuero común publicada por el Secretariado Ejecutivo del Sistema Nacional de Seguridad Pública (SESNSP), para identificar probables casos de manipulación y explorar los incentivos detrás de éstos.
Para empezar, la literatura (Nolan et al. 2011) define dos clases de manipulación: subregistro (es decir, eliminar por completo algunos delitos) y clasificación errónea (por ejemplo, clasificar a un homicidio doloso como culposo)[4]. En esta primera entrega, sólo nos concentraremos en identificar posibles ejemplos de subregistro de homicidios dolosos. En una siguiente, exploraremos casos de clasificación incorrecta entre homicidios dolosos y culposos. Finalmente, en una tercera entrega, discutiremos cómo un sistema de auditorías puede mejorar la calidad y veracidad de la información delictiva local, en la ausencia de mecanismos de validación y rendición de cuentas.
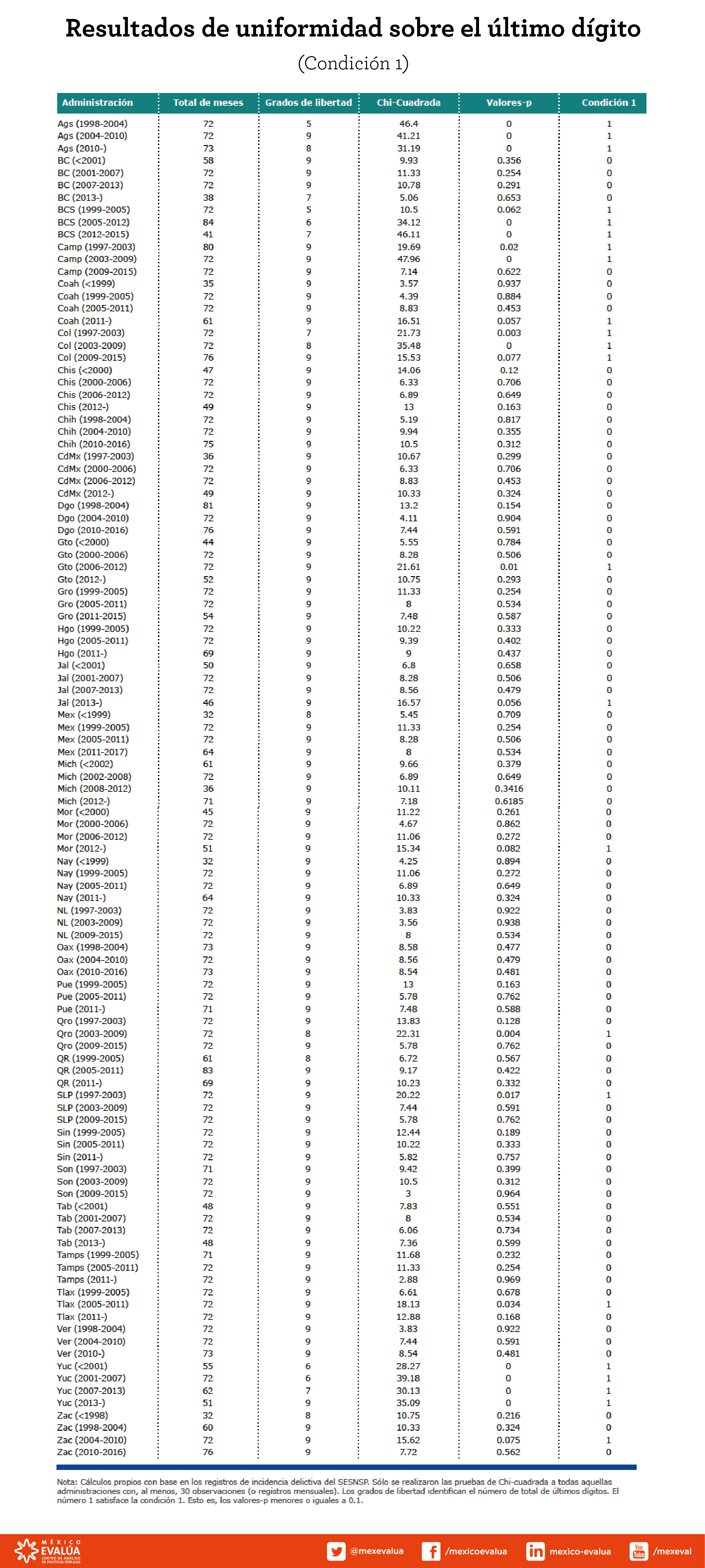
Para identificar casos de subregistro por administración de gobiernos estatales, explotamos las aplicaciones de análisis forenses[5] sobre las cifras de los homicidios dolosos, para detectar posibles anomalías en su registro, con base en un análisis del comportamiento de su último dígito[6]. Para esto, aplicamos exámenes estadísticos de uniformidad para identificar patrones anormales y no aleatorios en la distribución del último dígito de los homicidios, como si se tratase de una auditoría.
Dicho lo anterior, ¿qué entendemos por aleatorio y por uniforme?
Todos hemos jugado, alguna vez, “volados” con una moneda. Si la moneda es “justa”, cada una de sus dos caras tiene una probabilidad uniforme (o equivalente) de salir cuando se echa un volado, es decir, el sol tiene una probabilidad del 50 por ciento de ocurrencia, mientras que el águila el 50 por ciento restante. Entonces, si lanzamos 1 mil veces esta moneda al aire, esperaríamos observar, en promedio, que 500 veces resulte en sol y 500 veces en águila. Siguiendo esta analogía, ahora pensemos en un dado de 10 caras (decaedro). Si el dado es justo, entonces cada una de sus 10 caras tiene una probabilidad del 10 por ciento de ocurrencia.
Así pues, una distribución uniforme significa que el último dígito de los homicidios dolosos tiene la misma probabilidad de ocurrencia (esto es, el “0” tiene la misma frecuencia que el “1” o el “5” o el “8”, etc.) Por consiguiente, en ausencia de manipulación, el último dígito de los homicidios mensuales debería seguir la misma frecuencia estocástica que un dado “justo” en forma de decaedro (Mosimann et al. 2002).
Para identificar distribuciones digitales no-uniformes, empleamos la siguiente condición sugerida por Bernd Beber y Alexandra Scacco (2012), ambos profesores de la Universidad de Nueva York: en ausencia de manipulación, los números {0, 1, 2, …, 9} que pueden integrar al último dígito tienen una frecuencia uniforme o la misma probabilidad de ocurrencia.
En cambio, experimentos de laboratorio indican que las personas tienden a favorecer ciertos numerales sobre otros y, consiguientemente, este sesgo puede observarse mediante pruebas estadísticas.
Usamos una prueba chi-cuadrada de bondad de ajuste (chi-square goodness of fit) para evaluar si la distribución del último dígito del homicidio difiere de las proporciones hipotéticas de uniformidad.Analizamos a 109 administraciones estatales de un total de 136 cubiertas por el periodo. En promedio, cada administración tuvo 66 observaciones mensuales de homicidios, donde el mínimo fue 30[7] y el máximo 92. Además, se excluyó del análisis a todos los registros de homicidios mensuales sin datos o con una incidencia nula.

Como una primera aproximación al problema, la siguiente figura ilustra las distribuciones del último dígito de las estadísticas relativas a los homicidios dolosos por administración. A partir de los resultados de cada gobierno estatal, se puede observar que algunos de éstos se alejan de una distribución uniforme fijada en un 10 por ciento de ocurrencia para cada dígito.
Finalmente, el siguiente cuadro muestra las pruebas chi-cuadrada para cada una de las administraciones estatales analizadas. Con base en esta prueba, 23 de 136 gobernadores estatales parecen haber dejado algún rastro de manipulación. En particular, los gobiernos de Aguascalientes (gobernador Felipe González González, 1998-2004), Baja California Sur (gobernador Narciso Agúndez Montaño, 2005-2011), Campeche (gobernador Jorge Carlos Hurtado Valdez, 2003-2009), Colima[8] (gobernadores Gustavo Alberto Vázques Montes y Jesús Silverio Cavazos Ceballos, 2003-2009) y Yucatán(gobernador Patricio Patrón Laviada, 2001-2007) obtuvieron un valor-p cercano a 0[9], indicando que no cumplieron la hipótesis de uniformidad en el último dígito del homicidio doloso.
Algunos de estos casos podrían deberse a la suerte, pero es llamativa la distribución del último dígito de homicidios en estas cinco administraciones. A pesar de que éstas se caracterizaron por pocos registros de violencia letal, el homicidio es un acto fortuito cuya distribución debería ser, en todo caso, uniforme o equi-frecuente. En este sentido, como advierten Philip J. Boland y Kevin Hutchinson (2000), profesores de estadística de la Universidad Colegio Dublin y la Universidad Nacional de Irlanda respectivamente, cuando se solicita a personas anotar números de manera aleatoria, éstos suelen escoger con mayor frecuencia los números “1”, “2” y “3” –justamente las tercias digitales más frecuentes en las gubernaturas aquí señaladas– y en menor cantidad números grandes como el “5”, “6”, “8” y “9”.
En suma, las personas obedecen a conductas psicológicas que les impiden escoger y reescribir números de manera aleatoria, incluso cuando tienen incentivos para hacerlo. Este sesgo puede ser identificado mediante pruebas estadísticas sobre la uniformidad del último dígito.
Si bien nuestros resultados reflejan distribuciones anómalas en las estadísticas del homicidio doloso, con base en este ejercicio, se puede concluir que la falta de uniformidad puede deberse a la falta de infraestructura o capacidad de las procuradurías locales para clasificar y resolver delitos, y a posibles casos de subregistro y manipulación intencional, entre otros. En todo caso, antes de servir para señalar a algún gobierno estatal, estas pruebas deberían ser consideradas como diagnósticos para identificar focos rojos y complementarse con auditorías físicas de estadísticas delictivas que permitan, justamente, validar sus conclusiones.
* Jimena David y Jesús A. Gallegos son investigadores del Programa de Seguridad de México Evalúa (@mexevalua) y Jonathan Furszyfer es coordinador del mismo. Los autores agradecen los comentarios y edición de Laurence Pantin y el diseño de Miguel Cedillo. Este artículo está basado en el estudio de México Evalúa (2017) “Cada víctima cuenta: hacia un sistema de información delictiva confiable”.
Referencias
Beber, Bernd y Alexandra Scacco. 2012. “What the numbers say: a digit-based test for election fraud.” Political Analysis 20: 211-234.
Baesens, Bart, Véronique Van Vlasselaer y Wouter Verbeke. 2015. Fraud analytics using descriptive, predictive, and social network techniques: a guide to data science for fraud detection. New Jersey: Willey Press.
Boland, Phillip J. y Kevin Hutchinson. 2000. “Student selection of random digits.” Journal of the Royal Statistical Society. Series D (The Statistician) 49 (4): 519-529.
David, Jimena, Jonathan Furszyfer y Jesús A. Gallegos. 2017. Cada víctima cuenta: hacia un sistema de información delictiva confiable. Ciudad de México: México Evalúa, Centro de Análisis de Políticas Públicas A.C.
Mosimann, James E., Claire V. Wiseman y Ruth E. Edelman. 1995. “Data fabrication: can people generate random digits?” Accountability in Research 9: 75-92.
Mosimann, James E., John Dahlberg , Nancy Davidian y John Krueger. 2002. “Terminal digits and the examination of questioned data.” Accountability in Research 9 (2): 75-92.
Instituto Nacional de Estadística y Geografía. 2016. Encuesta Nacional de Acceso a la
Información Pública y Protección de Datos Personales. Acceso el 25 de enero, 2017. Disponible aquí.
Nolan, James J., Stephen M. Haas y Jessica S. Napier. 2011. “Estimating the impact of classification error on the ‘statistical accuracy’ of Uniform crime reports.” Journal of Quantitative Criminology 27: 497-519.
[1] Desarrollada por Instituto Nacional de Estadística y Geografía (Inegi) en colaboración con el Instituto Nacional de Transparencia, Acceso a la Información y Protección de Datos Personales (Inai). Población de 18 años y más que habita en áreas urbanas de 100 mil habitantes y más.
[2] En términos de pruebas de hipótesis estadísticas o métodos econométricos.
[3] Se denomina homicidio doloso a un subtipo del delito de homicidio que se caracteriza porque el victimario busca intencionadamente el resultado de muerte de la víctima, mientras que el homicidio culposo se refiere a la muerte del asegurado causada por hechos accidentales, fortuitos o involuntarios del causante, como consecuencia del proceder negligente.
[4] Supongamos que en una entidad se cometieron 100 homicidios dolosos en el mes de enero de 1997. La manipulación por subregistro implicaría eliminar 20 homicidios intencionales de los 100, reportando 80. Por otro lado, supongamos, ahora, que otra entidad enfrentó 100 homicidios, 50 dolosos y 50 culposos, en el mes de febrero de 1997. En caso de incurrir en la segunda clase de manipulación, es decir, clasificación incorrecta, la entidad ahora reporta 80 homicidios culposos y 20 dolosos, pero la incidencia total (100) se mantiene constante.
[5] Los análisis forenses digitales examinan datos estructurados para identificar manipulación financiera y electoral. Su objetivo consiste en descubrir y analizar patrones vinculados a actividades fraudulentas (Baessens 2015).
[6] Por ejemplo, si alguna demarcación en algún mes reportó 174 homicidios, sólo estudiamos el número 4. Si otra, para el mismo mes, reportó 38, extrajimos y analizamos el número 8.
[7] Esto es, en muestras mayores a 30 observaciones se espera una distribución normal de la variable de interés, a partir de los supuestos del Teorema Central del Límite.
[8] En este periodo, hubieron dos prefectos imperiales y dos interinos en el estado de Colima.
[9] En otras palabras, si repitiésemos 1,000 veces el comportamiento del último dígito de las entidades anteriores, se esperaría observar una sola vez un comportamiento uniforme y 999 veces un comportamiento anómalo.